
Le développement d’applications cloud natives constitue une évolution structurelle dans la conception logicielle moderne. Cette approche permet aux organisations de créer des systèmes robustes, scalables et résilients, capables de s’adapter aux besoins changeants du marché. Cependant, cette transition nécessite une compréhension précise des technologies d’orchestration, des pratiques DevOps et des enjeux de sécurité et de conformité, particulièrement dans le contexte réglementaire français et européen de 2026.
Au sommaire
- Les fondamentaux des applications cloud natives en 2026
- Architecture microservices : Docker, Kubernetes et service mesh
- Concevoir des APIs robustes pour le cloud natif
- CI/CD : automatiser build, test et déploiement
- Scalabilité et résilience : concevoir pour la haute disponibilité
- Sécurité et conformité : protéger vos applications cloud natives
- Se lancer concrètement : par où commencer ?
Les fondamentaux des applications cloud natives en 2026
Les applications cloud natives reposent sur quatre piliers architecturaux distincts. Premièrement, la décomposition en microservices remplace les architectures monolithiques traditionnelles, permettant une modularité accrue et des déploiements indépendants par composant. Deuxièmement, la conteneurisation encapsule chaque service avec ses dépendances dans une unité portable et reproductible.
Troisièmement, l’orchestration dynamique via des plateformes comme Kubernetes assure la gestion automatisée du cycle de vie des conteneurs, incluant l’équilibrage de charge, l’auto-scaling et la récupération sur panne. Quatrièmement, l’intégration des pratiques DevOps et CI/CD permet une automatisation de bout en bout, du développement à la production.
Une application cloud native est un système logiciel conçu spécifiquement pour exploiter les capacités du cloud computing : élasticité automatique des ressources, résilience par réplication distribuée, déploiements fréquents via CI/CD, et architecture microservices conteneurisée orchestrée par des plateformes comme Kubernetes.
Selon le dernier rapport annuel de la CNCF publié en janvier 2026, 59% des organisations déclarent désormais qu’une grande partie ou la quasi-totalité de leurs développements sont cloud natifs. Cette généralisation marque un tournant structurel dans l’industrie logicielle.
L’automatisation constitue le socle opérationnel de cette approche. Les applications cloud natives sont conçues pour être déployées, mises à jour et supervisées sans intervention manuelle. Cette automatisation réduit drastiquement les erreurs humaines et accélère les cycles de livraison, permettant des déploiements plusieurs fois par jour au lieu de versions trimestrielles.
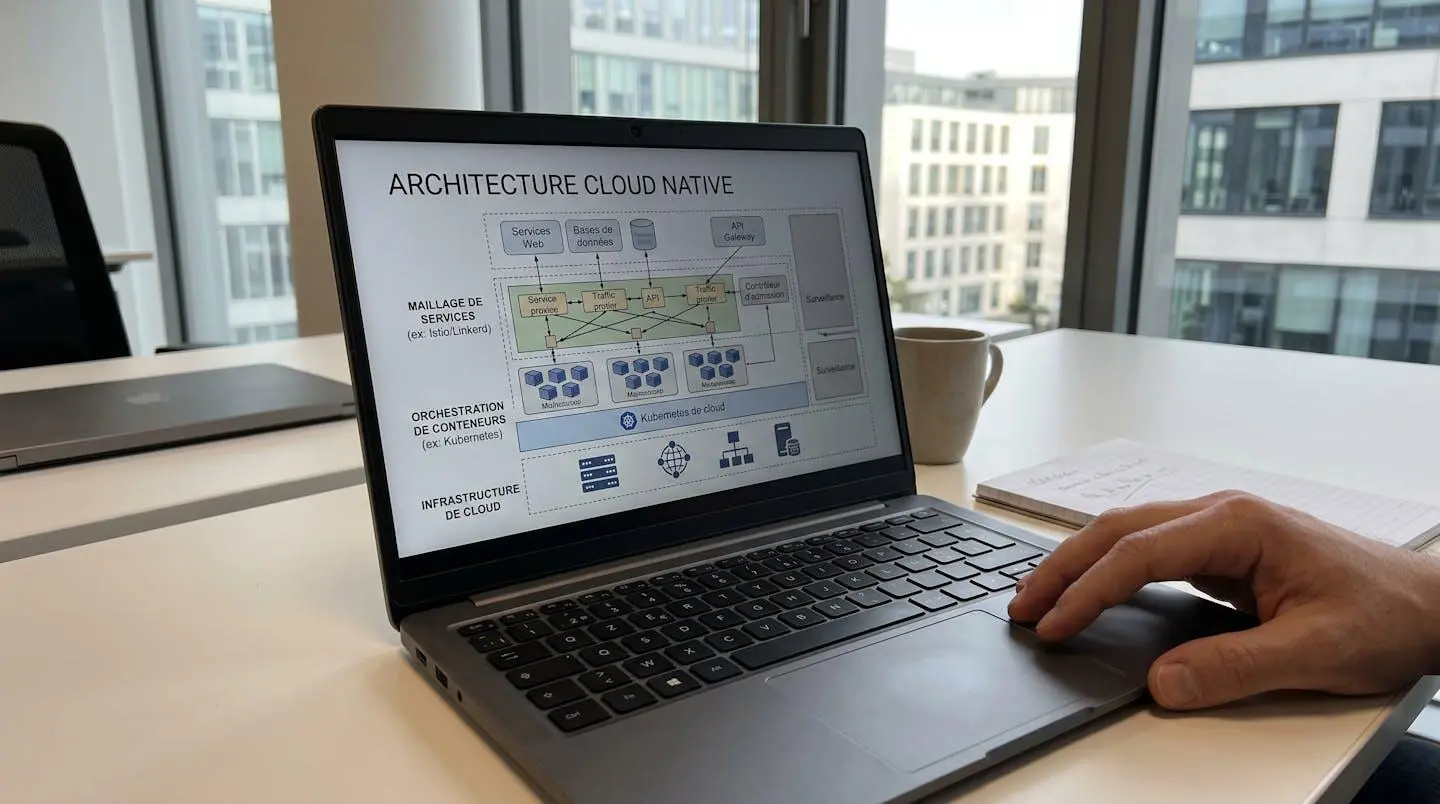
La résilience et la scalabilité sont intrinsèques à la conception. Les applications cloud natives tolèrent les pannes de composants individuels grâce à des mécanismes d’auto-réparation et de réplication. Elles s’adaptent automatiquement à la demande, augmentant ou réduisant les ressources selon le trafic observé. Cette élasticité optimise les coûts d’infrastructure tout en garantissant les performances attendues.
Pour comprendre pleinement le positionnement du cloud natif, il est utile de maîtriser les différences entre IaaS, PaaS et SaaS, ces modèles de services cloud sur lesquels reposent les architectures natives. L’approche cloud native se situe généralement au niveau PaaS et au-dessus, exploitant des services managés pour concentrer les efforts sur la logique métier plutôt que sur la gestion d’infrastructure.
Architecture microservices : Docker, Kubernetes et service mesh
L’architecture microservices décompose une application en services autonomes et faiblement couplés, chacun responsable d’un domaine fonctionnel précis. Cette approche offre une flexibilité d’évolution sans précédent : chaque service peut être développé, déployé et scalé indépendamment, sans impacter les autres composants du système. Cette modularité facilite également la répartition du travail au sein de grandes équipes de développement.
Docker s’est imposé comme le standard de facto pour la conteneurisation des microservices. Un conteneur encapsule l’application, ses dépendances système, ses bibliothèques et sa configuration dans une image portable, garantissant une exécution identique quel que soit l’environnement cible. Cette cohérence entre développement, tests et production élimine le syndrome classique « ça marche sur ma machine ». Les conteneurs offrent également une isolation au niveau processus, renforçant la sécurité sans la surcharge des machines virtuelles complètes.
Kubernetes est devenu l’orchestrateur de conteneurs dominant du marché. Il automatise le déploiement, la mise à l’échelle et l’exploitation d’applications conteneurisées à travers des clusters de machines. Selon le même rapport de la CNCF mentionné précédemment, 82% des utilisateurs de conteneurs exécutent désormais Kubernetes en production en 2025, contre 66% en 2023. Cette progression de 24 points en deux ans confirme son statut de plateforme de référence.
Kubernetes fonctionne selon un modèle déclaratif : vous définissez l’état souhaité de votre application via des manifestes YAML (nombre de réplicas, ressources allouées, stratégie de mise à jour), et le système converge automatiquement vers cet état. Si un pod tombe en panne, Kubernetes le redémarre. Si la charge augmente, il provisionne automatiquement de nouvelles instances selon les règles d’auto-scaling configurées.
Dans une infrastructure de production avec des dizaines de microservices et des centaines de pods déployés, l’exploitation d’une plateforme Kubernetes devient complexe et chronophage. La supervision continue, la gestion des mises à jour de sécurité, l’optimisation des performances et la résolution d’incidents nécessitent une expertise pointue. C’est pourquoi de nombreuses organisations s’appuient sur une TMA Cloud DevOps pour vos infrastructures critiques, garantissant une exploitation 24/7 par des équipes spécialisées tout en libérant les développeurs pour se concentrer sur la création de valeur métier.
82 %
Part des utilisateurs de conteneurs exécutant Kubernetes en production en 2025
Kubernetes fournit également des mécanismes natifs pour la gestion des configurations (ConfigMaps), des secrets (Secrets chiffrés), du stockage persistant (Persistent Volumes) et de l’exposition réseau (Services et Ingress). Cette richesse fonctionnelle en fait une véritable plateforme applicative, bien au-delà d’un simple orchestrateur de conteneurs.
Dans une architecture distribuée comprenant des dizaines voire des centaines de microservices, la gestion du trafic réseau, de la sécurité des communications et de l’observabilité devient rapidement problématique. Le service mesh Istio répond à ces défis en ajoutant une couche d’infrastructure dédiée à la communication inter-services. Istio injecte automatiquement un proxy sidecar (Envoy) dans chaque pod, interceptant toutes les communications entrantes et sortantes. Cette architecture permet de centraliser la gestion du routage avancé (canary deployment, A/B testing), du chiffrement mutuel TLS entre services, de la limitation de débit et de la résilience (circuit breaker, retry policies).
Certains composants nécessitent une gestion d’état local : bases de données distribuées (Cassandra, MongoDB), systèmes de messagerie (Kafka, RabbitMQ), ou caches distribués (Redis). Kubernetes propose les StatefulSets pour garantir une identité réseau stable pour chaque pod (nom DNS prévisible), un ordre de déploiement et de terminaison déterministe, et une association permanente avec des volumes de stockage persistant.
Concevoir des APIs robustes pour le cloud natif
Les APIs constituent l’interface de communication entre microservices et avec les systèmes externes. Une conception soignée de ces APIs est déterminante pour la maintenabilité, la performance et l’évolutivité de l’architecture globale. Les principes de conception REST reposent sur une représentation orientée ressources : chaque entité métier (utilisateur, commande, produit) est exposée via une URL unique, et les opérations CRUD sont mappées sur les verbes HTTP standards (GET, POST, PUT, DELETE).
REST offre une simplicité conceptuelle et une maturité éprouvée. Chaque endpoint expose une ressource spécifique avec une structure prédéfinie. Cette approche fonctionne bien pour des APIs publiques stables ou des services internes aux contrats clairement définis. L’utilisation de standards HTTP (codes de statut, en-têtes, caching) simplifie également l’intégration avec l’écosystème web existant.

GraphQL excelle dans les contextes où les clients ont des besoins d’interrogation variables. Plutôt que d’exposer des endpoints multiples, GraphQL propose un point d’entrée unique avec un langage de requête permettant aux clients de spécifier exactement les champs dont ils ont besoin. Cette flexibilité réduit le sur-fetching (récupération de données inutiles) et le sous-fetching (nécessité d’appels multiples pour agréger des données). Dans un environnement cloud natif où la latence réseau entre microservices est non négligeable, GraphQL peut réduire significativement le nombre d’appels en permettant l’agrégation de données provenant de plusieurs services en une seule requête.
La sécurisation des APIs dans une architecture distribuée nécessite un mécanisme d’authentification et d’autorisation décentralisé. OAuth 2.0 s’est imposé comme le standard pour l’autorisation déléguée, permettant à un service d’accéder à des ressources pour le compte d’un utilisateur sans connaître ses credentials. Le flux typique implique un authorization server centralisé délivrant des access tokens après authentification de l’utilisateur. Ces tokens, généralement au format JWT (JSON Web Tokens), sont ensuite transmis dans l’en-tête Authorization de chaque requête API.
Les JWT présentent l’avantage d’être auto-porteurs : toute l’information d’autorisation est encodée dans le token, évitant aux services de devoir interroger systématiquement une base centralisée. En pratique, il est recommandé d’implémenter systématiquement le chiffrement TLS pour toutes les communications API, même internes au cluster, de valider rigoureusement toutes les entrées utilisateur pour prévenir les injections, et d’appliquer le principe du moindre privilège en définissant des scopes OAuth granulaires par service.
Une documentation API claire et maintenue à jour est essentielle pour l’adoption par les équipes de développement. OpenAPI (anciennement Swagger) fournit une spécification standardisée pour décrire des APIs REST de manière machine-readable. Cette description formelle permet de générer automatiquement une documentation interactive (Swagger UI), des clients SDK dans différents langages, et même des serveurs mock pour les tests. Le versioning des APIs est une problématique critique dans les systèmes distribués. L’approche par URL (api/v1/, api/v2/) reste la plus explicite et la plus répandue, même si elle introduit une duplication temporaire du code serveur.
CI/CD : automatiser build, test et déploiement
L’intégration continue et le déploiement continu constituent le socle opérationnel des applications cloud natives. Ces pratiques permettent d’automatiser le cycle complet de livraison logicielle, réduisant drastiquement le temps entre l’écriture de code et sa mise en production. Selon le rapport State of DevOps 2024 de DORA (DevOps Research and Assessment), les équipes élites déploient 182 fois plus fréquemment que les équipes à faibles performances, avec des lead times 127 fois plus rapides et un taux d’échec de déploiement 8 fois inférieur.
Ces écarts spectaculaires démontrent que fréquence et stabilité ne s’opposent pas. Au contraire, déployer plus souvent force à améliorer l’automatisation, les tests et les mécanismes de rollback, ce qui in fine améliore la fiabilité globale du système. Seules 19% des organisations atteignent actuellement le niveau élite (déploiements plusieurs fois par jour), indiquant une marge de progression importante pour le secteur.
Un pipeline d’intégration continue commence dès le commit de code dans le repository Git. À chaque push ou pull request, le système déclenche automatiquement une série d’étapes : compilation du code source, exécution des tests unitaires et d’intégration, analyse statique de qualité (linting, détection de bugs potentiels), et scan de vulnérabilités de sécurité.
Jenkins reste une solution populaire pour sa flexibilité et son écosystème de plugins massif, bien qu’elle nécessite une infrastructure dédiée. GitLab CI et GitHub Actions intègrent nativement ces capacités dans leurs plateformes de gestion de code, simplifiant l’adoption pour les équipes déjà utilisatrices, bien que des outils spécialisés comme Spinnaker offrent des capacités avancées de déploiement multi-cloud. Ces plateformes modernes s’appuient sur des runners éphémères (conteneurs Docker ou machines virtuelles) garantissant des environnements de build propres et reproductibles.
L’étape de build produit généralement des artefacts immuables : images Docker taguées avec un identifiant unique (hash du commit, version sémantique). Ces images sont poussées vers un registry et deviennent les candidates au déploiement. Cette immutabilité garantit que l’artefact testé en pré-production est strictement identique à celui déployé en production.
Les environnements de tests virtuels jouent un rôle crucial dans cette phase. Pour approfondir cette dimension et optimiser vos cycles de tests automatisés, consultez les pratiques détaillées sur les environnements de tests virtuels pour développeurs, qui permettent de simuler des infrastructures complexes sans coût d’hébergement permanent.
Les stratégies de déploiement avancées minimisent le risque lors de la mise en production de nouvelles versions. Le déploiement bleu-vert maintient deux environnements identiques : l’un (bleu) sert le trafic de production, l’autre (vert) reçoit la nouvelle version. Après validation de la version verte, le trafic bascule instantanément via une modification de routage réseau. En cas de problème, un rollback immédiat rétablit le flux vers l’environnement bleu.
-
Push du code source vers le repository Git central
-
Compilation et création de l’image Docker
-
Exécution des tests unitaires et d’intégration automatisés
-
Analyse des vulnérabilités connues dans les dépendances
-
Déploiement automatique vers l’environnement de pré-production
-
Tests de bout en bout et validation manuelle des fonctionnalités critiques
-
Déploiement progressif en production avec monitoring actif
Le déploiement canary adopte une approche plus progressive : une fraction limitée du trafic (généralement 5-10%) est routée vers la nouvelle version. Les métriques clés (taux d’erreur, latence, charge serveur) sont surveillées en temps réel. Si elles restent dans les seuils acceptables, le pourcentage augmente graduellement jusqu’à 100%. Toute anomalie déclenche un rollback automatique. Le rolling update, natif dans Kubernetes, remplace progressivement les pods un par un ou par petits groupes.
L’observabilité est indissociable du déploiement continu. Sans visibilité en temps réel sur les métriques applicatives et systèmes, détecter une régression introduite par un déploiement devient impossible. Prometheus s’est imposé comme le standard de monitoring dans les environnements cloud natifs, particulièrement bien intégré avec Kubernetes. Prometheus fonctionne selon un modèle de pull : il scrape périodiquement les endpoints /metrics exposés par chaque service pour collecter des séries temporelles (CPU, mémoire, requêtes par seconde, latence, erreurs).
Grafana se connecte à Prometheus pour fournir une interface de visualisation riche. Les équipes construisent des dashboards personnalisés présentant les KPIs métier et techniques pertinents. Ces dashboards servent à la fois pour le monitoring quotidien et pour l’investigation d’incidents. Les alertes Prometheus peuvent également être configurées pour notifier (Slack, PagerDuty, email) dès qu’un seuil critique est franchi.
Scalabilité et résilience : concevoir pour la haute disponibilité
La scalabilité et la résilience constituent des propriétés architecturales fondamentales des systèmes cloud natifs, garantissant leur capacité à maintenir un service de qualité face à des charges variables et à des défaillances partielles. Ces caractéristiques ne peuvent pas être ajoutées après coup ; elles doivent être intégrées dès la conception.
Une architecture événementielle et asynchrone améliore drastiquement la scalabilité. Plutôt que des appels synchrones bloquants entre services, l’adoption de systèmes de messagerie distribués comme Apache Kafka ou RabbitMQ découple les producteurs et consommateurs d’événements. Cette approche permet de dimensionner indépendamment chaque composant selon sa charge spécifique et d’absorber les pics de trafic en mettant les messages en file d’attente.
Dans un contexte de messagerie asynchrone, chaque microservice consomme des événements à son rythme, traite la logique métier, et publie à son tour des événements pour les services abonnés. Cette chaîne asynchrone évite les timeouts en cascade et facilite l’insertion de nouveaux traitements sans modifier les producteurs existants.
Défis spécifiques des architectures distribuées : La latence réseau entre services devient non négligeable et variable. La cohérence forte des données est difficile à garantir sans impacter les performances ; la cohérence éventuelle devient la norme. Le debugging et le tracing d’une requête traversant 15 microservices différents nécessitent des outils spécialisés de tracing distribué comme Jaeger ou Zipkin. Ces compromis doivent être acceptés et gérés explicitement.
La résilience repose sur des patterns éprouvés. Le Circuit Breaker surveille les appels vers un service dépendant et passe en mode ouvert (bloquant les appels) si le taux d’échec dépasse un seuil. Cela évite de surcharger un service déjà défaillant et permet de retourner rapidement une erreur ou une réponse dégradée. Après un timeout configuré, le circuit repasse en mode semi-ouvert pour tester la récupération du service.
Les stratégies de retry avec backoff exponentiel gèrent les erreurs transitoires (réseau instable, service temporairement surchargé). Plutôt qu’un retry immédiat qui aggraverait la charge, le délai entre tentatives augmente exponentiellement (1s, 2s, 4s, 8s) avec un jitter aléatoire pour éviter l’effet thundering herd où tous les clients retentent simultanément.
La conception pour le chaos (Chaos Engineering) consiste à injecter volontairement des pannes dans l’environnement de production pour valider la résilience réelle du système. Des outils comme Chaos Monkey (Netflix) arrêtent aléatoirement des instances, simulent des latences réseau ou saturent des ressources. Ces tests révèlent les failles de résilience avant qu’elles ne se manifestent lors d’incidents réels.
Enfin, les bases de données distribuées comme Apache Cassandra, etcd ou CockroachDB garantissent la disponibilité des données même en cas de panne de nœuds. Ces systèmes répliquent les données sur plusieurs nœuds et régions géographiques, tolèrent les partitions réseau selon le théorème CAP, et offrent une cohérence ajustable selon les besoins métier.
Sécurité et conformité : protéger vos applications cloud natives
La sécurité dans les environnements cloud natifs nécessite une approche multi-couches couvrant le code, les conteneurs, l’orchestration, le réseau et les données. Comme le souligne l’état de la menace cloud publié par l’ANSSI en février 2025, les trois vecteurs d’attaque principaux ciblant le cloud sont les attaques lucratives (ransomware, exfiltration), l’espionnage étatique, et la déstabilisation via DDoS.
Le principe du moindre privilège doit s’appliquer à tous les niveaux. Chaque conteneur, chaque service account Kubernetes, chaque utilisateur ne doit disposer que des permissions strictement nécessaires. Dans Kubernetes, l’utilisation de Role-Based Access Control (RBAC) permet de définir finement qui peut effectuer quelles actions sur quelles ressources. Les service accounts applicatifs ne doivent jamais disposer de droits cluster-admin.
La gestion sécurisée des secrets (mots de passe, clés API, certificats) est critique. Stocker des credentials en clair dans le code source ou les variables d’environnement constitue une vulnérabilité majeure. Des solutions comme HashiCorp Vault ou les services managés des cloud providers (AWS Secrets Manager, Azure Key Vault) centralisent le stockage chiffré des secrets, gèrent leur rotation automatique, et fournissent un audit trail complet des accès.
Le chiffrement doit être systématique. TLS 1.3 pour toutes les communications réseau, même internes au cluster (via service mesh ou mutual TLS natif Kubernetes). Chiffrement at-rest pour les volumes persistants contenant des données sensibles. Chiffrement des sauvegardes. Ces mécanismes protègent contre l’interception du trafic et l’accès non autorisé aux disques.
L’approche DevSecOps intègre la sécurité dès le développement et tout au long du pipeline CI/CD. Les scans de vulnérabilités d’images Docker (Trivy, Clair) doivent bloquer le déploiement si des CVE critiques sont détectées. L’analyse statique de code (SonarQube, Snyk) identifie les failles de sécurité potentielles avant même le commit. Les tests de sécurité automatisés (OWASP ZAP, tests de pénétration) s’exécutent dans les environnements de staging.
Concernant la conformité réglementaire française et européenne, l’ANSSI recommande de privilégier des offres cloisonnées de type SecNumCloud pour les activités sensibles. Cette qualification garantit un haut niveau d’exigence technique, opérationnel et juridique, incluant l’indépendance vis-à-vis des lois extraterritoriales comme le Cloud Act américain et la conformité native au RGPD.
Pour les données de santé, la certification HDS (Hébergeur de Données de Santé) est obligatoire en France. Les organisations traitant des données personnelles doivent documenter leurs mesures techniques (pseudonymisation, minimisation, durées de rétention) et organisationnelles (AIPD, registre des traitements) conformément au RGPD.
Checklist sécurité : les 8 points essentiels avant la mise en production
- Activer le chiffrement TLS 1.3 pour toutes les communications réseau, internes et externes
- Centraliser la gestion des secrets avec Vault ou équivalent, interdire les credentials en clair
- Appliquer le principe du moindre privilège via RBAC Kubernetes et IAM cloud provider
- Scanner automatiquement les images Docker pour détecter les CVE critiques
- Mettre en place un cloisonnement réseau avec Network Policies Kubernetes
- Centraliser et superviser les logs de sécurité avec une solution SIEM
- Implémenter une authentification multi-facteurs pour tous les accès d’administration
- Vérifier la conformité RGPD : localisation des données, durées de rétention, mesures de pseudonymisation
La journalisation centralisée et la supervision continue des événements de sécurité permettent la détection précoce d’anomalies. Des solutions comme la stack ELK (Elasticsearch, Logstash, Kibana) ou des SIEM managés agrègent les logs de tous les composants, détectent les patterns suspects via machine learning, et génèrent des alertes pour investigation. L’ANSSI souligne que de nombreux incidents récents auraient pu être évités avec une supervision adéquate des systèmes d’information.
Se lancer concrètement : par où commencer ?
La transition vers le cloud natif ne s’improvise pas. Elle nécessite une approche méthodique combinant montée en compétences, choix technologiques adaptés et démarrage progressif via un projet pilote à périmètre maîtrisé. Vouloir migrer l’ensemble du SI d’un coup constitue une erreur fréquente menant à l’échec ou à l’enlisement.
Commencez par identifier un microservice candidat idéal pour le pilote : une fonctionnalité métier relativement isolée, avec des dépendances limitées, ne traitant pas de données ultra-sensibles, et portée par une équipe motivée techniquement. Ce premier projet permettra d’acquérir l’expérience opérationnelle (création de pipelines CI/CD, gestion Kubernetes, observabilité) sans risquer la stabilité des systèmes critiques.
La formation des équipes est un investissement indispensable. Les compétences requises (conteneurisation, orchestration Kubernetes, pratiques DevOps, sécurité cloud) ne s’acquièrent pas instantanément. Prévoyez des formations certifiantes (CKA pour Kubernetes, certifications cloud providers), des ateliers pratiques internes, et le temps nécessaire pour expérimenter sur des environnements non productifs.
Le choix entre cloud public (AWS, Azure, GCP), cloud souverain français (OVHcloud, Scaleway, Outscale), ou infrastructure on-premise dépend de vos contraintes de conformité, de budget et de compétences. Les clouds publics majeurs offrent un écosystème de services managés très riche réduisant la charge opérationnelle, mais impliquent une dépendance et des questions de souveraineté. Les solutions souveraines répondent aux exigences de localisation des données en France tout en proposant des services Kubernetes managés conformes SecNumCloud.
Établissez une stratégie FinOps dès le départ. Les coûts cloud peuvent dériver rapidement sans gouvernance : instances surdimensionnées, stockage non utilisé, snapshots oubliés, trafic réseau inter-régions. Mettez en place des budgets et alertes, utilisez les outils de cost management natifs, et intégrez les métriques de coût dans les dashboards de supervision aux côtés des métriques techniques. La scalabilité automatique doit s’accompagner de politiques de downscaling pour éviter les gaspillages.
Documentez systématiquement vos choix architecturaux, vos runbooks opérationnels et vos procédures d’incident. Dans un système distribué complexe, cette documentation devient cruciale pour l’onboarding de nouveaux membres, la résolution rapide d’incidents et la capitalisation des apprentissages. Les Architecture Decision Records (ADR) formalisent les décisions importantes et leur contexte.
Pour aller plus loin dans l’optimisation de vos développements cloud natifs et découvrir des techniques complémentaires d’amélioration continue, consultez les astuces incontournables pour améliorer des logiciels, qui couvrent des aspects de qualité de code, de tests et de performance applicative essentiels à la réussite de vos projets.
Vos questions sur le développement cloud natif
Faut-il migrer toutes les applications existantes vers le cloud natif ?
Non. Les applications legacy stables, peu évolutives et sans contrainte de scalabilité peuvent rester sur leur architecture actuelle. La migration cloud natif se justifie pour les applications nécessitant une agilité de déploiement élevée, une scalabilité automatique ou une architecture distribuée. Privilégiez une approche sélective basée sur les gains métier attendus plutôt qu’une migration systématique.
Quel budget prévoir pour une infrastructure Kubernetes en production ?
Le budget dépend du dimensionnement et du modèle d’hébergement. Comptez entre 500€ et 2000€ par mois pour un cluster managé petit à moyen (3-10 nœuds) chez les cloud providers majeurs. Ajoutez les coûts de stockage, de bande passante, de monitoring et éventuellement de support ou TMA. Pour un cluster auto-géré on-premise, l’investissement matériel initial et les ressources humaines spécialisées représentent des coûts significatifs souvent sous-estimés.
Quelles compétences développer en priorité dans les équipes ?
Trois domaines prioritaires : la maîtrise de Kubernetes (déploiements, services, ingress, scaling), la conteneurisation Docker (création d’images optimisées, registries, sécurité), et les pratiques CI/CD (pipelines automatisés, stratégies de déploiement, tests). Investissez également dans la culture DevOps (collaboration dev/ops, automatisation, amélioration continue) et les fondamentaux de sécurité cloud (gestion secrets, RBAC, chiffrement).
Comment gérer la complexité opérationnelle accrue ?
L’observabilité devient cruciale : implémentez monitoring (Prometheus), logging centralisé (ELK stack) et tracing distribué (Jaeger) dès le départ. Automatisez au maximum via GitOps et infrastructure as code. Documentez systématiquement. Envisagez une TMA spécialisée pour l’exploitation 24/7 si vos équipes internes manquent de bande passante ou d’expertise. La complexité se maîtrise par l’outillage, les processus et la montée en compétences progressive.
Quelle est la durée réaliste pour un premier projet pilote réussi ?
Comptez entre 3 et 6 mois pour un pilote complet incluant formation initiale des équipes, mise en place de l’infrastructure, développement ou migration d’un premier microservice, création du pipeline CI/CD et passage en production avec monitoring. Ce délai varie selon la maturité DevOps existante et la complexité du microservice choisi. Ne sous-estimez pas le temps d’apprentissage et d’ajustement organisationnel.
Comment garantir la conformité RGPD avec une architecture distribuée ?
Documentez précisément les flux de données personnelles entre microservices, implémentez la pseudonymisation et le chiffrement systématiques, définissez des durées de rétention automatisées par type de donnée, et assurez la traçabilité des accès via logs centralisés. Privilégiez des cloud providers offrant des datacenters français ou européens et des DPA (Data Processing Agreements) conformes. Pour les données sensibles, envisagez les offres qualifiées SecNumCloud garantissant souveraineté et conformité renforcée.
Kubernetes est-il indispensable pour faire du cloud natif ?
Kubernetes s’est imposé comme le standard d’orchestration avec 82% d’adoption en production, mais des alternatives existent pour des besoins spécifiques : Docker Swarm pour des déploiements simples, Nomad de HashiCorp pour des workloads hétérogènes, ou les offres serverless managées (AWS Lambda, Azure Functions) éliminant totalement la gestion d’infrastructure. Choisissez selon votre complexité applicative, vos compétences internes et vos contraintes de portabilité entre clouds.